
ABSTRAK
Keandalan sistem meningkatkan kepercayaan, tetapi juga dapat merusak kinerja pemantauan manusia dan pada gilirannya memengaruhi kepercayaan. Efek ini bervariasi di berbagai kesalahan. Studi ini menguji efek keandalan otomasi (100%, 75%, dan 50%) dan pembingkaiannya (deskripsi keandalan negatif dan positif), dan bias kesalahan (alarm palsu dan miss) pada kepercayaan pengguna dan faktor-faktor terkaitnya dalam sistem mengemudi otomatis (ADS). Setiap peserta menyelesaikan 16 uji coba dengan tugas kolaborasi manusia-kendaraan dalam simulator mengemudi statis. Hasilnya menunjukkan bahwa ADS dengan keandalan yang lebih tinggi berdampak positif pada kepercayaan pengguna, tetapi berdampak negatif pada kesadaran situasi. Kepercayaan pengguna lebih tinggi dalam peristiwa alarm palsu (FA) daripada dalam peristiwa miss, tetapi keberhasilan tugas dan kesadaran situasi lebih tinggi dalam peristiwa miss. Studi ini mengungkapkan korelasi negatif yang tidak biasa antara kepercayaan dan kesadaran situasional dalam kolaborasi manusia-kendaraan dan memberikan wawasan yang mungkin ke dalam faktor internal bias kesalahan dalam otomasi. Temuan kami memiliki implikasi untuk strategi pengungkapan keandalan dan kalibrasi kepercayaan.
1 Pendahuluan
Teknologi otomatis yang terlibat dalam industri kendaraan merupakan tren yang tak terelakkan untuk masa depan, karena sistem pengemudian otomatis (ADS) dapat mengurangi kemacetan, mengurangi kelelahan pengemudi, meningkatkan keselamatan jalan, dan meningkatkan efisiensi bahan bakar (Daziano et al. 2017 ; Fagnant dan Kockelman 2015 ). Membagi tanggung jawab untuk kontrol kendaraan dengan sistem juga memungkinkan pengemudi untuk menggunakan waktu tempuh untuk tugas-tugas yang tidak terkait dengan mengemudi (NDRT) (Fagnant dan Kockelman 2015 ). Namun, banyak pengguna mungkin memendam ketidakpercayaan berdasarkan praduga mereka atau liputan berita tentang kegagalan ADS (Shi et al. 2021 ), dan selanjutnya dapat menyebabkan tidak digunakannya sebagian atau seluruh fungsi otomatisasi (Parasuraman dan Riley 1997 ). Kasus kesalahan ADS dapat memengaruhi kepercayaan pengguna dan penggunaan ADS, dan faktor kunci dalam interaksi manusia-kendaraan ini adalah keandalan otomatisasi dan variabel yang mungkin terkait dengannya (Mishler dan Chen 2023 ).
Masalah keandalan menjadi perhatian khusus dalam konteks otomasi tingkat lanjut. Studi sebelumnya telah menguji pengaruh keandalan otomasi terhadap kepercayaan, yang menunjukkan bahwa peningkatan keandalan otomasi mengarah pada peningkatan kepercayaan atau ketergantungan pengguna (Large et al. 2019 ; Mishler dan Chen 2023 ), tetapi dapat secara serius merusak kemampuan mereka untuk memantau secara efektif, yang selanjutnya memengaruhi hubungan kepercayaan manusia-otomasi (Bailey dan Scerbo 2007 ). Dan pengguna tidak peka terhadap keandalan sistem jika tidak ada deskripsi atau umpan balik yang akurat tentang hal itu (Wang et al. 2009 ), terutama ketika sistem tidak gagal tetapi membuat alarm palsu, karena alarm palsu (FA) dan kegagalan memengaruhi kepercayaan melalui dua proses independen, dan FA otomasi mungkin lebih merusak daripada kegagalan (Bliss dan Acton 2003 ; Meyer 2001 ). Eksperimen simulasi berkendara eksploratif dilakukan dalam studi ini, dengan beberapa tingkat keandalan, kerangka deskripsi untuk tingkat keandalan, dan kejadian bias kesalahan yang mensimulasikan berbagai skenario berkendara untuk memeriksa bagaimana kepercayaan pengguna bervariasi saat berkolaborasi dengan ADS.
1.1 Kepercayaan pada Otomasi
Kepercayaan dalam otomatisasi mengacu pada kepercayaan manusia dalam sistem otomatisasi, yang bergantung pada kinerja, proses, atau tujuan sistem otomatis (Lee dan Moray 1992 ), dan menentukan penggunaan otomatisasi. Kepercayaan yang tidak tepat dalam otomatisasi dapat menyebabkan penyalahgunaan, penghentian penggunaan, dan penyalahgunaan otomatisasi (Parasuraman dan Riley 1997 ). Lee dan See ( 2004 ) dapat dikatakan memberikan salah satu deskripsi paling komprehensif untuk menjelaskan peran kepercayaan dalam otomatisasi dan mengusulkan metode untuk mendefinisikan kepercayaan yang tepat dalam otomatisasi yang menekankan bahwa kepercayaan yang berlebihan dan ketidakpercayaan adalah kalibrasi yang buruk di mana kepercayaan tidak sesuai dengan kemampuan sistem. Itu berarti, dengan interaksi, manusia dapat memahami kemampuan dan keterbatasan sistem dan mengkalibrasi kepercayaan mereka sebagaimana mestinya (Parasuraman dan Riley 1997 ).
Studi terkini menerapkan konsep kepercayaan manusia dalam ADS, di mana pengemudi harus percaya bahwa kendaraan akan merespons bahaya yang tidak terduga persis seperti yang diprogramkan untuk dilakukannya. Pengemudi dapat belajar dari waktu ke waktu melalui interaksi dengan ADS tentang kemampuannya dan mengkalibrasi kepercayaan mereka sebagaimana mestinya. Dalam proses ini, kesalahan otomatisasi adalah salah satu faktor paling berpengaruh yang memengaruhi kepercayaan, biasanya bergantung pada frekuensi kesalahan, prediktabilitas, dan tingkat keparahan. Untuk kesalahan otomatisasi kecil, penurunan kepercayaan mungkin kecil dan tidak penting (Beggiato et al. 2015 ; Mishler dan Chen 2023 ). Kesalahan otomatisasi besar atau serius seperti yang menyebabkan kendaraan menabrak akan jauh lebih kuat (de Visser et al. 2018 ). Menurunnya kepercayaan dapat mendorong pengemudi untuk mengabaikan atau menonaktifkan ADS jika kepercayaan pengemudi tidak pulih dari penurunan tersebut, yang merupakan konsekuensi langsung dari ketidakpercayaan dan dapat merusak kinerja seluruh tim manusia-kendaraan (Bliss dan Acton 2003 ). Bukti ekstensif menunjukkan bahwa memahami dimensi kepercayaan dalam ADS akan memungkinkan perancang untuk menciptakan sistem yang memaksimalkan kolaborasi manusia-kendaraan dan dengan demikian meningkatkan keselamatan jalan di masa mendatang.
Cara mengukur kepercayaan dalam otomatisasi juga merupakan topik utama. Dalam studi eksperimental dalam otomatisasi penerbangan, kepercayaan biasanya diukur melalui dua perilaku: kepatuhan (operator menanggapi peringatan otomatisasi) dan ketergantungan (operator menanggapi non-peringatan otomatisasi) (Chavaillaz et al. 2016 ; Dixon dan Wickens 2006 ; Johnson et al. 2004 ). Pengukuran tersebut dapat digunakan dalam sistem peringatan yang memungkinkan perilaku manusia dievaluasi dalam satu kali uji coba (Holthausen et al. 2020 ). Dalam konteks mengemudi otomatis, beberapa perilaku pengemudi dalam ADS tidak dapat diklasifikasikan hanya sebagai apakah pengemudi menanggapi peringatan otomatisasi atau tidak. Bahasa Indonesia : Dalam beberapa studi empiris yang menguji kepercayaan pengemudi pada ADS, pengukuran fisiologis (seperti dilatasi pupil (Stapel et al. 2022 ), respons kulit galvanik (Morris et al. 2017 ), dan pelacakan mata (Hergeth et al. 2016 )) atau psikologis (seperti variabilitas model mental (Beggiato et al. 2015 )) telah diusulkan, yang mengarah pada hasil yang beragam. Masih belum jelas seberapa valid fisiologi atau psikologi dalam jangka waktu yang lebih lama, yang diagregasi dari kejadian yang berulang. Ada juga studi yang menggunakan kesadaran situasi (SA) dan keandalan yang dirasakan (PR) sebagai variabel proksimal kepercayaan (He et al. 2022 ; Petersen et al. 2019 ; Washburn et al. 2020 ). Pada akhirnya, cara paling langsung untuk mengukur kepercayaan pada ADS adalah dengan bertanya kepada peserta melalui skala standar atau yang diadaptasi. Skala yang sering digunakan adalah “Trust in Automation Scale” yang diusulkan oleh Jian et al. ( 2000 ), yang mengklasifikasikan kepercayaan menjadi kompetensi, keandalan, prediktabilitas, dan keyakinan. Cramer dkk. ( 2008 ) mengusulkan skala yang berisi 12 item, enam di antaranya diadaptasi dari Jian dkk. ( 2000 ). Atas dasar ini, Holthausen dkk. ( 2020 ) mengembangkan “Skala Kepercayaan Situasional untuk Mengemudi Otomatis”, yang menggabungkan elemen penting dari model Hoff dan Bashir ( 2015 ), seperti potensi risiko dan manfaat konteks mengemudi, atau efikasi diri pengemudi untuk mengoperasikan kendaraan otomatis. Secara umum, satu kemungkinan untuk mengevaluasi kepercayaan dalam konteks interaksi manusia-kendaraan tertentu mungkin adalah mengintegrasikan pengukuran dimensi yang berbeda, dengan menganalisis tugas dan skenario mengemudi.
1.2 Keandalan, Bias Kesalahan dan Pembingkaian
Melalui meta-analisis faktor-faktor yang memengaruhi kepercayaan dalam otomatisasi, Hancock et al. ( 2011 ) menemukan bahwa keandalan adalah salah satu faktor utama yang memengaruhi pengembangan kepercayaan manusia. Azevedo-Sa et al. ( 2021 ) mendefinisikan keandalan sebagai risiko internal dan menunjukkan bahwa keandalan dapat memengaruhi kepercayaan pengguna secara signifikan karena risiko dalam berkendara telah ditemukan untuk menentukan apakah kepercayaan diterjemahkan menjadi perilaku percaya yang sebenarnya. Sebagian besar penelitian mengenai kolaborasi manusia-kendaraan telah menunjukkan bahwa ketika ADS tidak terlalu andal, kolaborator manusia perlu bereaksi dan mengoreksi malfungsi yang terjadi, dan kemudian kepercayaan mereka akan menurun dan mereka kurang bergantung pada sistem (Bailey dan Scerbo 2007 ; Dixon et al. 2007 ; Dzindolet et al. 2003 ) dalam berbagai konteks otomatisasi berkendara, termasuk seluruh ADS (Large et al. 2019 ), sistem penghindaran tabrakan (Bliss dan Acton 2003 ), dan navigasi di dalam kendaraan (R. Ma dan Kaber 2007 ).
Bahasa Indonesia: Ketika otomatisasi gagal, biasanya menghasilkan satu dari dua jenis galat. FA adalah indikasi yang tidak tepat dari suatu kejadian, sementara miss berarti galat tidak terdeteksi (Dixon et al. 2006 ), secara kolektif disebut sebagai bias galat. Sebelumnya, diasumsikan bahwa FA akan lebih merusak kinerja keseluruhan daripada miss, serta memengaruhi kepatuhan dan ketergantungan operator (Dixon et al. 2007 ), dan FA yang terus-menerus atau meluas akan menyebabkan kepercayaan operator yang lebih rendah pada otomatisasi (Dixon et al. 2007 ; Johnson et al. 2004 ). FA juga rentan menyebabkan gangguan, yang memerlukan beban kerja yang lebih tinggi dan beberapa tindakan yang tidak perlu dari kolaborator manusia (Dixon dan Wickens 2006 ). Faktanya, semua fenomena ini terkait erat. Kepatuhan dan ketergantungan sebagai respons yang terlihat secara eksternal terhadap kepercayaan, dan perbedaan utama di antara keduanya dalam interaksi manusia-otomatisasi adalah tidak adanya isyarat (Chancey et al. 2017 ). FA biasanya disertai dengan kejadian yang menonjol secara perseptual, yaitu kesalahan yang lebih terlihat atau berkesan daripada kesalahan (Dixon et al. 2007 ), dan juga membutuhkan lebih banyak intervensi dari kolaborator, sehingga menyebabkan kepercayaan yang lebih rendah pada sistem otomatis dan alarm yang sebenarnya diabaikan, yang dikenal sebagai sindrom “serigala penangis” (Breznitz 1984 ; Parasuraman dan Riley 1997 ). Meskipun ada bukti ini, penting untuk dicatat bahwa para ahli mungkin kurang reseptif terhadap kesalahan daripada FA, karena biaya yang terkait dengan hilangnya kejadian kritis dalam sistem persinyalan dapat menjadi bencana (Chancey et al. 2017 ; Masalonis dan Parasuraman 1999 ). Dalam kolaborasi manusia-kendaraan, dampak dari kedua bias kesalahan ini masih harus diperiksa.
Kepercayaan pengguna juga dibentuk oleh informasi apa pun yang mereka terima sebelum interaksi manusia-otomatisasi tentang kemungkinan kesalahan atau biaya kegagalan (Groom et al. 2011 ; Wang et al. 2009 ). Informasi tentang keandalan otomatisasi ini disebut sebagai framing (Hallahan 1999 ). Framing membantu orang bernegosiasi dan menafsirkan interaksi dengan tepat dengan mendorong aktivasi struktur pengetahuan, atau skema yang relevan (Tannen dan Wallat 1987 ), dan dengan demikian secara akurat mencocokkan kepercayaan mereka dengan tingkat keandalan aktual dalam interaksi berikutnya (Wang et al. 2009 ). Telah dibuktikan bahwa otomatisasi dengan framing menghasilkan evaluasi yang lebih tinggi daripada yang tidak (Groom et al. 2011 ; Wang et al. 2009 ). Framing tinggi yang menggambarkan otomatisasi sebagai kemampuan tinggi menghasilkan evaluasi yang lebih positif daripada framing rendah (Paepcke dan Takayama 2010 ; Washburn et al. 2020 ). Khususnya, efek Framing juga memengaruhi sikap manusia (Tversky dan Kahneman 1981 ) – yaitu menyampaikan pesan yang sama dengan cara positif atau negatif, orang biasanya lebih sensitif terhadap yang negatif, karena deskripsi negatif menunjukkan kemungkinan kerugian, sementara deskripsi positif menunjukkan kemungkinan manfaat (Vliegenthart 2012 ; C. Zhang et al. 2022 ). Perbedaan ini akan lebih jelas dalam tugas berisiko tinggi (Tversky dan Kahneman 1981 ), seperti kerja sama manusia-kendaraan untuk mengemudi otonom. Karena framing negatif menyiratkan kerugian dari kemungkinan tabrakan, sementara framing positif menyiratkan manfaat dari sekadar berkendara yang aman.
1.3 Studi Saat Ini
Penelitian sebelumnya secara umum menunjukkan bahwa keandalan ADS memiliki dampak signifikan pada kepercayaan manusia dan bahwa bias kesalahan merupakan faktor kunci dalam kolaborasi manusia-otomatisasi, tetapi tidak ada satu pun dari penelitian tersebut yang berfokus pada efek pembingkaian dalam interaksi manusia-kendaraan dan mengadopsi variabel-variabel ini sebagai variabel independen untuk memeriksa efeknya dan menganalisis faktor internalnya pada kepercayaan pengguna dalam kolaborasi manusia-kendaraan. Penelitian saat ini membahas kesenjangan pengetahuan tentang keandalan otomatisasi dan pembingkaiannya, serta bias kesalahan dalam sistem mengemudi, dan memberikan fokus khusus pada interaksi keduanya dengan memeriksa pengembangan kepercayaan. Pertanyaan penelitian utama dari penelitian saat ini adalah: Bagaimana keandalan sistem mengemudi otomatis dan pembingkaiannya, serta bias kesalahan memengaruhi kepercayaan pengguna? Oleh karena itu, kami merancang dan melakukan eksperimen simulasi mengemudi untuk menyelidiki efek dari ketiga variabel ini pada kepercayaan peserta dalam skenario simulasi mengemudi dengan tugas kolaborasi manusia-kendaraan. Untuk mengeksplorasi efeknya dengan jelas, kami mengecualikan variabel yang tidak terkait dengan tugas kolaborasi dalam skenario mengemudi untuk mengurangi beban kerja kognitif peserta. Percobaan ini dirancang dengan skenario sederhana dan tugas kolaborasi, yang melibatkan berkendara di jalan dengan volume lalu lintas rendah dan menghadapi rintangan bergerak dengan tujuan yang tidak diketahui saat tiba di persimpangan.
Dalam studi eksperimen tugas kolaborasi manusia-kendaraan, biasanya, jika sistem menangani tugas mengemudi dengan baik, pengemudi didorong untuk terlibat dalam NDRT (Radlmayr et al. 2014 ). Ketika situasi yang kompleks muncul, sistem memberikan informasi tertentu kepada pengemudi, mempertahankan kesadaran situasional pengemudi, atau mencari intervensi pengemudi (Guo et al. 2018 ; Xing et al. 2021 ). Dalam studi saat ini, bentuk dasar kolaborasi manusia-kendaraan mirip dengan pendahulunya. Efeknya diperiksa dalam skenario mengemudi tertentu, yang meliputi tugas sekunder NDRT, dan tugas utama kolaborasi manusia-kendaraan. Kinerja peserta dalam tugas kolaborasi dianggap sebagai tanda luar yang intuitif dan ukuran kepercayaan yang objektif pada ADS. Selain itu, skala yang diminta untuk diisi oleh peserta di akhir setiap tugas kolaborasi digunakan sebagai pengukuran subjektif kepercayaan.
2 Bahan dan Metode
2.1 Peserta
Perhitungan ukuran sampel a-priori dilakukan dengan menggunakan perangkat lunak G*Power (Versi 3.1.9.7) (Faul et al. 2007 ). Untuk daya yang diasumsikan sebesar 0,80, alfa sebesar 0,05, dan ukuran efek sebesar 0,25, kami memiliki ukuran sampel yang diproyeksikan sebesar 30 partisipan. Oleh karena itu, penelitian ini merekrut 30 partisipan dari dua universitas, yang mana 15 di antaranya mengidentifikasi diri sebagai perempuan dan 15 sebagai laki-laki. 28 partisipan adalah mahasiswa (93%) dan 2 karyawan (7%). Usia berkisar antara 20 hingga 31 tahun, dengan rata-rata 24,7 tahun (SD = 8,13). Semua partisipan melaporkan memiliki pendengaran dan penglihatan normal atau dikoreksi ke normal. Tidak ada partisipan yang sebelumnya pernah mengalami simulator mengemudi. Mereka menandatangani persetujuan dan formulir GDPR sebelum mereka mengambil bagian dalam penelitian dan diberi kompensasi dengan voucher belanja senilai 10 euro setelah penelitian.
2.2 Aparatus dan Stimulus
Percobaan dilakukan di Jerman di Departemen Informatika LMU, menggunakan simulator mengemudi terbuka dengan basis tetap dengan tiga monitor tampilan 43 inci (resolusi 3840 × 2160) yang menyediakan bidang pandang horizontal sekitar 135°, yang menampilkan skenario mengemudi utama. Frekuensi pengambilan sampel simulator mengemudi adalah 60 Hz. Roda kemudi, pedal, dan tongkat persneling selama percobaan ditutup, untuk menghilangkan rasa peserta mengendarai mobil yang dikemudikan secara manual (Lihat Gambar 1 ). Peserta duduk sekitar 120 cm dari monitor utama. Sistem audio surround menyediakan suara mesin dan objek lalu lintas di sekitarnya dalam skenario, yang ditempatkan di bawah tiga monitor.
Skenario berkendara dengan ADS tinggi dalam studi ini disimulasikan dalam Unity 3D (Versi 2018.4.14f1) dan dijalankan pada ketiga monitor simulator berkendara. Dalam skenario tersebut, terdapat jalan perkotaan 2 jalur dengan lalu lintas rendah, panjangnya sekitar 1,2 km dengan persimpangan di ujung jalan. Visibilitas rendah dalam kondisi berkabut diketahui meningkatkan kemungkinan tabrakan (Yan et al. 2014 ). Untuk meningkatkan kemungkinan kegagalan sistem kendaraan, kami mengatur lingkungan cuaca pada hari berkabut yang memungkinkan pengemudi melihat rintangan sejauh 130 m. Dengan demikian, kecepatan berkendara otomatis (sekitar 60 km/jam) ditetapkan sedikit di bawah batas kecepatan banyak jalan perkotaan. Jadi, peserta dapat mengidentifikasi rintangan yang dapat dicapai setelah sekitar 7 detik (yaitu, batas waktu untuk tugas kolaborasi pada tampilan konsol tengah) pada kecepatan ini. Butuh waktu sekitar 65 detik bagi kendaraan untuk melaju sejauh 1,2 km dan mencapai persimpangan.
Dalam percobaan tersebut, para peserta duduk di simulator. Di sisi kanan, layar tambahan (Mac Book Pro, 13 inci, M1, 2020) dipasang untuk mensimulasikan tampilan konsol tengah kendaraan, memungkinkan para peserta untuk berpartisipasi dalam NDRT, dan bertindak sebagai antarmuka untuk tugas-tugas kolaborasi, dan juga digunakan untuk mengisi skala di akhir setiap percobaan. Tugas-tugas kolaboratif dan NDRT dibuat dalam program web yang dibuat dengan JavaScript, tempat para peserta dapat berinteraksi dengan touchpad dan keyboard.
2.3 Tugas Eksperimen
Bagi para peserta, setiap percobaan dalam eksperimen tersebut terdiri dari dua tugas. Tugas kolaborasi utama adalah bahwa ketika kendaraan hendak mencapai persimpangan, peserta akan melihat antarmuka status kendaraan diperbesar pada layar tambahan (lihat NDRT ke C pada Gambar 2 ). Antarmuka ini menunjukkan pandangan mata burung dari kendaraan yang ditumpangi peserta, dan memberikan informasi berikut: kondisi jalan, tingkat pengisian/bensin saat ini, kecepatan saat ini, dan informasi tugas kolaborasi. Pop-up tugas kolaborasi di tengah bersifat tembus cahaya, dengan sistem mendeteksi informasi, saran mengemudi, dan hitung mundur tugas. Peserta dapat memilih apakah akan lurus atau mengerem dengan menekan tombol “atas” atau “bawah” pada keyboard berdasarkan saran pada pop-up dan penilaian mereka sendiri terhadap skenario tersebut.
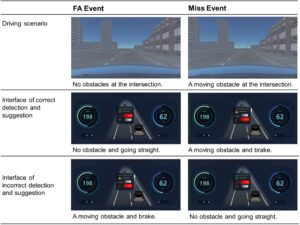
Perlu dicatat bahwa tidak seperti sistem sinyal, yang hanya memberi peringatan saat mendeteksi kesalahan, ADS dalam studi ini menyediakan informasi deteksi dan saran berkendara pada setiap percobaan. Dan informasi dan saran selalu diberikan sebagaimana mestinya. Artinya, jika sistem mendeteksi dengan benar, sistem akan memberikan informasi yang benar dan saran berkendara yang sesuai. Gambar 3 menggambarkan skenario berkendara dan antarmuka status kendaraan saat sistem andal atau tidak andal untuk dua peristiwa bias kesalahan. Terlepas dari apakah informasi sistem itu benar, tugas kolaborasi akan berhasil selama respons peserta benar. Jika tugas kolaborasi berhasil, dalam peristiwa FA, kendaraan akan mengerem pada jarak tertentu dari pejalan kaki; dalam peristiwa gagal, kendaraan akan melaju lurus melalui persimpangan yang kosong. Jika gagal, dalam peristiwa FA, kendaraan akan melaju ke persimpangan dan mengalami tabrakan kecil dengan pejalan kaki; dalam peristiwa gagal, kendaraan akan mengerem dan berhenti di persimpangan yang kosong tanpa alasan.
Tugas sekunder NDRT dalam penelitian ini adalah permainan kata, yang dimodifikasi dari penelitian Jarosch et al. ( 2019 ). Peserta harus mendeteksi semua kata yang dimulai dengan “p” setiap kali kata tersebut ditampilkan di layar tambahan dengan menekan tombol “spasi”, di antara kata acak yang dimulai dengan “b,” “q,” “p” dan “d.”
Setelah setiap tugas mengemudi, peserta diminta untuk mengisi tiga skala. Di akhir semua percobaan, peserta akan menjawab beberapa pertanyaan dalam wawancara singkat yang terkait dengan percobaan untuk melengkapi beberapa bagian percobaan yang belum dijelaskan. Semua skala dan garis besar wawancara disajikan dalam Informasi Pendukung S1: File Tambahan 1 .
2.4 Desain Percobaan
Desain campuran 3 × 2 × 2 digunakan dalam penelitian ini. Tingkat reliabilitas merupakan faktor antar-subjek (tinggi, sedang, rendah). Peristiwa bias galat (FA dan miss) dan framing (positif dan negatif) merupakan faktor dalam-subjek yang muncul dalam urutan yang seimbang di setiap kelompok. Setiap partisipan menjalani 16 kali percobaan, dengan 4 kali pengulangan kondisi framing dan kondisi peristiwa bias galat.
Keandalan sistem dalam eksperimen dimanipulasi di 3 kondisi eksperimen dengan memvariasikan persentase deteksi dan saran yang benar yang diberikan oleh ADS. Dalam kondisi keandalan tinggi, sedang, dan rendah, 100%, 75%, dan 50% dari deteksi dan saran benar, masing-masing. Bukti menunjukkan bahwa batas bawah keandalan otomasi yang dapat diterima adalah 70%–80% (Johnson et al. 2004 ; Rovira et al. 2014 ). Dengan demikian, pengaturan ketiga kondisi keandalan ini dapat mewakili otomasi sempurna, otomasi yang dapat diterima, dan otomasi yang tidak dapat diterima. Karena keandalan adalah variabel antar-subjek, 30 peserta secara acak ditugaskan ke 1 dari 3 kelompok kondisi keandalan.
Peristiwa bias kesalahan merujuk pada peristiwa berkendara yang terjadi saat peserta hendak mencapai persimpangan di ADS. Untuk peristiwa FA, tidak ada pejalan kaki di persimpangan, tetapi sistem berpotensi mendeteksi rintangan yang bergerak di depan dan menyarankan pengereman. Untuk peristiwa Miss, ada pejalan kaki di sisi jalan yang hendak menyeberang jalan, tetapi sistem berpotensi mendeteksi tidak ada rintangan dan menyarankan untuk melaju lurus. Lihat Gambar 3 .
Pembingkaian dalam studi ini adalah deskripsi keandalan ADS, yang disajikan pada layar tambahan di awal setiap percobaan, dengan dua kondisi positif dan negatif, yang menggambarkan peluang keberhasilan atau kegagalan dalam tugas utama. Bukti menunjukkan bahwa kepercayaan konsumen terhadap teknologi baru berasal dari keseimbangan risiko yang dirasakan dan manfaat yang dirasakan (Ali et al. 2021 ; Featherman et al. 2021 ). Pembingkaian positif menyiratkan peluang bahwa peserta akan berkendara dengan aman melalui persimpangan, sedangkan pembingkaian negatif menyiratkan peluang bahwa peserta akan bertabrakan dengan pejalan kaki di persimpangan. Lihat Tabel 1 untuk informasi lebih lanjut tentang pembingkaian dalam tiga kondisi keandalan.
| Keandalan sistem | Pembingkaian positif | Pembingkaian negatif |
|---|---|---|
| Tinggi | Sistem ini memiliki peluang yang sangat tinggi untuk mendorong keberhasilan tugas. | Sistem ini memiliki peluang yang sangat rendah untuk gagal menjalankan tugas. |
| Sedang | Sistem memiliki peluang relatif tinggi dalam mendorong keberhasilan tugas. | Sistem ini memiliki peluang relatif rendah untuk mengalami kegagalan tugas penggerak. |
| Rendah | Sistem memiliki peluang yang rendah dalam mendorong keberhasilan tugas. | Sistem memiliki peluang tinggi untuk menyebabkan kegagalan tugas. |
Baik bias kesalahan maupun pembingkaian merupakan variabel dalam subjek, sehingga partisipan diharuskan untuk berpartisipasi dalam keempat kondisi untuk kedua variabel tersebut. Untuk menghilangkan pengaruh urutan percobaan, 3 kelompok yang terdiri dari 16 percobaan simulasi mengemudi diseimbangkan dengan kotak Latin, lalu 10 set urutan dipilih secara acak dari 16 set urutan. Akhirnya, diperoleh 3 kelompok yang terdiri dari 10 set urutan percobaan yang berbeda.
2.5 Variabel Terikat
Selama semua perjalanan, pengukuran perilaku kinerja peserta selama tugas kolaborasi dan pengukuran subjektif yang diisi dalam serangkaian skala telah diperoleh sebagai variabel dependen. Kinerja peserta termasuk kepatuhan, waktu respons (RT), dan keberhasilan tugas dalam tugas kolaborasi. Kepatuhan didefinisikan sebagai apakah peserta merespons sama seperti yang disarankan sistem dalam tugas kolaborasi; RT mengacu pada waktu untuk respons pertama peserta terhadap tugas kolaborasi. Keberhasilan tugas kolaborasi mengacu pada apakah kendaraan mengerem pada jarak tertentu dari pejalan kaki atau melaju lurus melalui persimpangan yang kosong.
Pengukuran subjektif meliputi kepercayaan, persepsi keandalan (PR), dan kesadaran situasi (SA). Kepercayaan diukur dengan Situational Trust Scale for Automated Driving (STS-AD) yang terdiri dari 6 item: kepercayaan, kinerja, NDRT, risiko, penilaian, dan reaksi (Holthausen et al. 2020 ). Skala PR adalah skala yang diadaptasi dari Washburn et al. ( 2020 ) Reliability Questionnaire dan Kidd and David ( 2003 ) Subscale of Reliability , yang terdiri dari 5 pertanyaan (lihat Tabel 1 ). Adapted Situational Awareness Rating Technique (SART) Taylor ( 1990 ) digunakan untuk mengukur SA partisipan, yang terdiri dari 9 pertanyaan dalam dimensi ketidakstabilan, kompleksitas, variabilitas situasi, gairah, konsentrasi, pembagian perhatian, Spare Mental Capacity, kuantitas informasi, dan keakraban dengan situasi. Ketiga skala tersebut menggunakan skala Likert 5 poin yang berkisar dari 1 hingga 5 dengan “Sangat Tidak Setuju” hingga “Sangat Setuju” atau “Sangat Rendah” hingga “Sangat Tinggi”.
2.6 Prosedur
Setelah tiba di laboratorium, setiap peserta diberi tahu tujuan utama penelitian dan diminta untuk melengkapi formulir persetujuan dan lembar demografi. Mereka diminta untuk duduk di simulator dan didorong untuk menyesuaikan kursi kendaraan agar dapat menjangkau layar tambahan dengan nyaman. Kemudian, para peserta mengikuti sesi perkenalan dan praktik tugas yang berlangsung sekitar 8 menit dengan 2–3 kali uji coba dan membahas dua kondisi kejadian bias galat untuk berlatih dan membiasakan diri dengan tugas-tugas tersebut. Selama sesi ini, para peserta diberi tahu bahwa mereka harus memperlakukan eksperimen tersebut seolah-olah mereka sedang berkendara di jalan sungguhan dan menyelesaikan tugas-tugas utama dan sekunder sebaik mungkin.
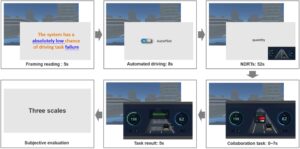
Setelah sesi praktik, serangkaian 16 uji coba formal dimulai. Untuk setiap uji coba, peserta diberi tugas untuk berkolaborasi dalam mengemudi dan melakukan NDRT. Pertama, kerangka keandalan sistem disajikan pada layar tambahan melalui teks positif atau negatif. Kerangka teks ini akan berlangsung selama 5 detik dan kata keterangan serta kata sifat untuk tingkat keandalan dalam teks disorot untuk memastikan bahwa peserta menangkap informasi tersebut. Kemudian autopilot dihidupkan. Peserta dapat menikmati beberapa detik berkendara melalui monitor simulator dan melihat kendaraan melaju secara otomatis di jalan kota yang berkabut. Setelah bunyi bip, peserta harus mengikuti NDRT pada layar tambahan selama 52 detik hingga kendaraan hampir mencapai persimpangan dan antarmuka status kendaraan muncul pada layar tambahan yang menggantikan antarmuka NDRT. Peserta diminta untuk memilih untuk mematuhi atau tidak mematuhi saran dalam waktu 7 detik. Setelah mengemudi, peserta menyelesaikan tiga skala berdasarkan perjalanan yang baru saja selesai. Gambar 2 mengilustrasikan monitor skenario mengemudi dan antarmuka pada layar tambahan yang dapat dilihat peserta selama prosedur uji coba. Di antara setiap dua uji coba, ditegaskan kembali bahwa para peserta sekarang akan mengalami ADS yang berbeda dari pemasok yang berbeda. Desain seperti itu diterapkan untuk menghilangkan efek pembingkaian dan hasil dari uji coba sebelumnya. Selain itu, para peserta diminta untuk beristirahat selama 1 atau 2 menit sebelum melanjutkan ke uji coba berikutnya.
Di akhir dari semua 16 percobaan, peserta akan menjawab pertanyaan dalam wawancara singkat. Kemudian biaya partisipasi diberikan dan percobaan berakhir. Total durasi prosedur percobaan terdiri dari empat sesi dan sekitar 80 menit (lihat Gambar 4 ).

3 Hasil
Data eksperimen dari 30 peserta dirangkum, termasuk kinerja peserta dan data skala setelah mengemudi. Karena data skala yang dikumpulkan dalam eksperimen berasal dari pengukuran subjektif, alfa Cronbach pertama-tama digunakan untuk menentukan tingkat konsistensi dan keandalan untuk skala Kepercayaan, PR, dan SA. Nilai alfa Cronbach yang dihitung untuk Kepercayaan, PR, dan SA masing-masing adalah 0,809, 0,865, dan 0,785, yang menunjukkan bahwa semua respons dapat diandalkan.
Mengingat bahwa penelitian ini bertujuan untuk menganalisis hubungan antara variabel, analisis statistik dilakukan dengan menggunakan pendekatan korelasional. Uji Shapiro-Wilk dan Plot QQ pertama kali digunakan untuk memeriksa kenormalan semua variabel dependen, karena ukuran sampel eksperimen tidak melebihi 100 (Zhang dan Wu 2005 ). Variabel dependen yang terdistribusi normal dan memenuhi asumsi homogenitas varians (uji Levene) dianalisis menggunakan ANOVA. Untuk data yang tidak terdistribusi normal, variabel diskrit dan kontinu dianalisis menggunakan uji Mann-Whitney (dua variabel kondisi) dan uji Kruskal-Wallis (tiga variabel kondisi). Regresi Logistik Biner digunakan untuk memprediksi variabel biner. Tingkat alfa ditetapkan pada 0,05 untuk semua uji statistik. Semua analisis diproses menggunakan SPSS Statistics.
Mengenai wawancara pasca-eksperimental, pendekatan analisis tematik yang diadaptasi dari Braun dan Clarke ( 2006 ) dipilih sebagai metodologi dalam wawancara pasca-eksperimental kami. Penulis pertama melakukan proses pengkodean, berdasarkan konten semantik transkrip, menggunakan kutipan mentah sebagai kode. Kode-kode tersebut disortir ke dalam kategori tematik berdasarkan pengulangan, persamaan, dan perbedaan (Ryan dan Bernard 2003 ). Dalam setiap kategori tematik, kode-kode tersebut selanjutnya dibedakan dan disortir ke dalam sub-tema. Kemudian penulis kedua meninjau definisi dan nama-nama tema dan memberikan umpan balik mengenai analisis, dan para penulis bersama-sama memutuskan revisi.
3.1 Statistik Deskriptif
Statistik deskriptif untuk kelompok kombinasi level setiap variabel dependen ditunjukkan pada Tabel 2. Dari statistik deskriptif, tiga pengukuran kinerja partisipan, skor Kepercayaan, dan skor PR, menunjukkan konsistensi tinggi. Karena kesederhanaan tugas kolaborasi, rasio kepatuhan dan rasio keberhasilan tugas adalah 100% di beberapa kelompok, terutama dalam kondisi reliabilitas tinggi. RT terpendek ( M = 0,875, SD = 0,607) untuk tugas kolaborasi berada pada kelompok miss* negatif reliabilitas tinggi*. Kepercayaan tertinggi ( M = 4,19, SD = 0,393) dan skor PR ( M = 4,38, SD = 0,510) berada pada kelompok FA* positif reliabilitas tinggi*. Rasio kepatuhan terendah ( M = 50, SD = 0,506) dan skor Kepercayaan terendah ( M = 2,97, SD = 0,614) berada pada kelompok miss* positif reliabilitas rendah*. RT terpanjang ( M = 1,88, SD = 0,939) berada pada kelompok FA* negatif dengan reliabilitas rendah. Tingkat keberhasilan terendah ( M = 88, SD = 0,420) berada pada kelompok FA* positif dengan reliabilitas rendah. Skor PR terendah ( M = 2,89, SD = 0,770) berada pada kelompok miss* negatif dengan reliabilitas rendah.
| C | Tingkat kepatuhan (%) | RT | Tingkat keberhasilan | Memercayai | hubungan masyarakat | SA | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| M | SD | M | SD | M | SD | M | SD | M | SD | M | SD | |
| HR* FA* NF | 100 | 0.00 | .975 | 0.48 | 100 | 0.00 | 4.00 | 0.41 | Jam 4.30 | 0.54 | 2.55 | 0.64 |
| HR* nona* NF | 100 | 0.00 | .875 | 0.61 | 100 | 0.00 | 4.03 | 0.46 | 4.28 | 0.53 | 2.91 | 0.63 |
| SDM* FA* PF | 100 | 0.00 | 1.20 | 0.56 | 100 | 0.00 | 4.19 | 0.39 | 4.38 | 0.51 | 2.56 | 0.67 |
| HR* nona* PF | 100 | 0.00 | 1.00 | 0,50 | 100 | 0.00 | 3.98 | 0.41 | 4.26 | 0,60 | 2.92 | 0,58 |
| Tn.* FA* NF | 80.0 | 0.41 | 1.42 | 0.63 | 95.0 | 0.22 | 3.55 | 0.41 | 3.82 | 0,65 | 2.73 | 0.39 |
| MR* nona* NF | 75.0 | 0.44 | 1.05 | 0,75 | 100 | 0.00 | 3.42 | 0.38 | 3.60 | 0,79 | Jam 3.30 | 0.40 |
| Tn.* FA* PF | 75.0 | 0.44 | 1.48 | 0,75 | 98.0 | 0.16 | 3.40 | 0.57 | 3.73 | 0,77 | 2.84 | 0.37 |
| Tn.* nona* PF | 75.0 | 0.44 | 1.15 | 0.62 | 100 | 0.00 | 3.22 | 0.68 | 3.58 | 0.76 | 3.33 | 0.33 |
| LR* FA* NF | 53.0 | 0.51 | 1.88 | 0,94 | 93.0 | 0.27 | 3.17 | 0,556 | 3.07 | 0.66 | 3.02 | 0.49 |
| LR* rindu* NF | 53.0 | 0.51 | 1.32 | 0.73 | 98.0 | 0.16 | 3.15 | 0.63 | 2.89 | 0,77 | 3.54 | 0.57 |
| LR* PF* YA* | 53.0 | 0.51 | 1.75 | 0.67 | 88.0 | 0.34 | 3.08 | 0.64 | 3.22 | 0.762 | 3.02 | 0.48 |
| LR* rindu* PF | 50.0 | 0.51 | 1.35 | 0.53 | 100 | 0.00 | 2.97 | 0.61 | 2.92 | 0.843 | 3.47 | 0,65 |
| Total | 76.0 | 0.43 | 1.29 | 0.72 | 98.0 | 0.16 | 3.51 | 0.66 | 3.67 | 0.866 | 3.02 | 0.61 |
Singkatan: FA, kejadian FA; HR, keandalan tinggi; LR, keandalan rendah; Miss, kejadian gagal; MR, keandalan sedang; NF, pembingkaian negatif; PF, pembingkaian positif.
Skor SA menunjukkan hasil yang berbeda dari variabel dependen lainnya. Skor SA tertinggi ( M = 3,54, SD = 0,565) berada pada kelompok negatif miss* dengan reliabilitas rendah dan terendah ( M = 2,55, SD = 0,636) berada pada kelompok negatif FA* dengan reliabilitas tinggi.
3.2 Kinerja Tugas Kolaborasi
Kinerja tugas kolaborasi mencakup kepatuhan peserta, waktu respons (RT), dan keberhasilan tugas, yang merupakan indikator perilaku kepercayaan peserta terhadap ADS. Tingkat kepatuhan yang lebih tinggi dan RT yang lebih pendek berarti bahwa peserta lebih bersedia mengikuti saran sistem dalam tugas kolaborasi, sementara tingkat keberhasilan tugas yang lebih tinggi menunjukkan kualitas kolaborasi yang lebih tinggi.
Data kepatuhan peserta dianalisis menggunakan Regresi Logistik Biner untuk memastikan efek keandalan sistem, bias kesalahan, dan pembingkaian pada kemungkinan bahwa seorang peserta akan mengikuti saran ADS. Model regresi logistik secara statistik signifikan, χ 2 (4) = 131,84, p < 0,001. Model tersebut menjelaskan 36,0% (Nagelkerke R 2 ) dari varians dalam kepatuhan dan mengklasifikasikan 76,0% kasus dengan benar. Uji Hosmer dan Lemeshow menunjukkan kecocokan yang baik dari model regresi logistik, χ 2 (8) = 0,237, p > 0,05. Peserta dalam kondisi keandalan sedang 2,98 kali lebih mungkin untuk mengikuti saran ADS daripada dalam kondisi keandalan rendah, Wald χ 2 (1) = 20,017, p < 0,05. Tingkat kepatuhan lebih rendah untuk kondisi reliabilitas rendah (M = 52,0%, SD = 0,501) dibandingkan dengan kondisi reliabilitas sedang (M = 76,0%, SD = 0,427) dan kondisi reliabilitas tinggi (M = 100,0%, SD = 0,000). Pengaruh bias kesalahan dan pembingkaian pada kepatuhan peserta tidak signifikan secara statistik, p > 0,05.
Data RT tidak mengungkapkan outlier tetapi tidak terdistribusi secara normal, D(480) = 0,793, p < 0,05. Pengujian menunjukkan efek signifikan reliabilitas pada RT, H(2) = 49,53, p < 0,05, dan perbedaan signifikan antara kondisi reliabilitas tinggi (peringkat rata-rata = 192,24), kondisi reliabilitas sedang (peringkat rata-rata = 241,15), dan kondisi reliabilitas rendah (peringkat rata-rata = 288,11), p < 0,05 untuk semua perbandingan, yang menunjukkan bahwa RT untuk tugas kolaborasi manusia-kendaraan lebih pendek dengan reliabilitas yang lebih tinggi. Efek bias kesalahan dan pembingkaian pada RT partisipan tidak signifikan secara statistik, p > 0,05.
Data keberhasilan tugas dianalisis menggunakan Regresi Logistik Biner untuk memastikan dampak variabel independen terhadap kemungkinan peserta gagal dalam tugas kolaborasi. Model regresi logistik signifikan secara statistik, χ 2 (4) = 23,304, p < 0,001. Model menjelaskan 22,7% (Nagelkerke R 2 ) dari varians keberhasilan tugas, dan mengklasifikasikan 97,5% kasus dengan benar. Uji Hosmer dan Lemeshow menunjukkan kecocokan yang baik dari model regresi logistik, Wald χ 2 (5) = 0,885, p > 0,05. Bias kesalahan adalah satu-satunya variabel yang signifikan secara statistik, χ 2 (1) = 5,55, p < 0,05. Tingkat keberhasilan tugas bagi partisipan dalam kondisi miss event (M = 100,0%, SD = 0,065) adalah 11,95 kali lebih tinggi daripada dalam kondisi FA event (M = 95,0%, SD = 0,210). Meskipun prediktabilitas reliabilitas tidak signifikan secara statistik, p > 0,05, tingkat keberhasilan tugas bagi partisipan dalam kondisi reliabilitas sedang (M = 98,0%, SD = 0,136) adalah 3,21 kali daripada dalam kondisi reliabilitas rendah (M = 95,0%, SD = 0,231), χ 2 (1) = 2,91, p = 0,088. Efek framing pada keberhasilan tugas juga tidak signifikan secara statistik, p > 0,05.
3.3 Kepercayaan
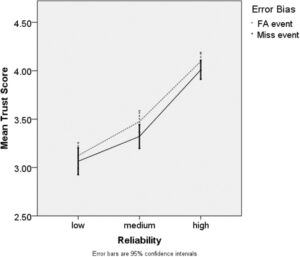
Skala Likert 5 poin, 6-item digunakan untuk mengukur kepercayaan peserta pada ADS setelah tugas kolaborasi. Pengujian menunjukkan data terdistribusi secara normal, D (160) = 0,987, p > 0,05 dalam kondisi reliabilitas rendah. Dengan demikian, analisis parametrik dilakukan. ANOVA Tiga Arah mengungkapkan pengaruh signifikan pada kepercayaan reliabilitas, F (2, 468) = 104,23, p < 0,05, η 2 p = 0,375. Uji Post Hoc menunjukkan perbedaan signifikan antara ketiga kondisi reliabilitas ini, p = 0,000 untuk semua perbandingan. Skor kepercayaan rata-rata adalah 4,05 (SD = 0,609), 3,40 (SD = 0,531), dan 3,09 (SD = 0,423) untuk kondisi reliabilitas tinggi, sedang, dan rendah. Ada pula efek signifikan bias galat pada kepercayaan, F (1, 468) = 2,844, p < 0,05, η 2 p = 0,375, yang menunjukkan kepercayaan yang lebih tinggi pada kondisi kejadian FA daripada pada kondisi kejadian tidak terjadi. Skor Kepercayaan rata-rata untuk kejadian FA dan kondisi kejadian tidak terjadi adalah 3,57 (SD = 0,647) dan 3,46 (SD = 0,672). Gambar 5 menggambarkan kepercayaan partisipan dalam semua kondisi keandalan dan bias galat. Tidak ada efek signifikan pembingkaian pada Kepercayaan, F (2, 468) = 2,844, p = 0,092, η 2 p = 0,006, meskipun skor kepercayaan rata-rata dalam kondisi pembingkaian negatif ( M = 3,56, SD = 0,596) secara numerik lebih tinggi daripada dalam kondisi pembingkaian positif ( M = 3,47, SD = 0,718). Perbedaan untuk perbandingan interaksi tidak signifikan, p > 0,05.
3.4 Keandalan yang Dirasakan
Skor PR diperoleh dengan merata-ratakan skor dalam skala Likert 5-item, 5-poin, yang tidak terdistribusi normal, D (480) = 0,952, p < 0,05. Analisis non-parametrik diterapkan. Ada efek signifikan reliabilitas pada PR, H (2) = 181,44, p < 0,05, dan perbedaan signifikan antara kondisi reliabilitas tinggi (peringkat rata-rata = 344,70), kondisi reliabilitas sedang (peringkat rata-rata = 240,03), dan kondisi reliabilitas rendah (peringkat rata-rata = 136,78), p < 0,05 untuk semua perbandingan, yang menunjukkan bahwa skor PR lebih tinggi dalam ADS dengan reliabilitas yang lebih tinggi. Uji Mann-Whitney mengungkapkan bahwa tidak ada efek signifikan pada PR partisipan dari bias kesalahan dan pembingkaian, p > 0,05.
3.5 Kesadaran Situasi
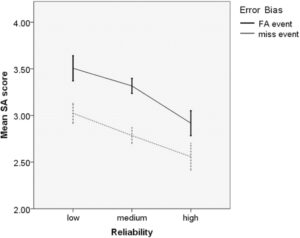
Skor SA peserta diperoleh dengan merata-ratakan skor pada skala SA 9-item, 5-poin. Pengujian menunjukkan bahwa data terdistribusi secara normal, D (160) = 0,985, p > 0,05 dalam kondisi reliabilitas sedang. ANOVA Tiga Arah menunjukkan bahwa efek utama reliabilitas signifikan, F (2, 468) = 40,24, p 0,05, η 2 p = 0,147. Uji Post Hoc menunjukkan perbedaan signifikan antara tiga kondisi reliabilitas ( p < 0,05 untuk semua perbandingan). Skor SA rata-rata adalah 2,74 (SD = 0,648), 3,05 (SD = 0,457), dan 3,26 (SD = 0,599) untuk kondisi reliabilitas tinggi, sedang, dan rendah. Ada pula efek signifikan bias kesalahan pada SA, F (1, 468) = 90,111, p < 0,05, η 2 p = 0,161, yang menunjukkan skor SA yang lebih tinggi dalam kondisi kejadian tidak terjadi daripada dalam kondisi kejadian FA. Skor SA rata-rata untuk kondisi kejadian tidak terjadi dan kejadian FA adalah 3,25 (SD = 0,588) dan 2,79 (SD = 0,548). Tidak ditemukan efek signifikan dari pembingkaian, dan efek interaksi pada SA partisipan, p > 0,05. Skor SA partisipan antara kelompok faktor yang signifikan secara statistik dilaporkan dalam Gambar 6 .
3.6 Wawancara Pasca Eksperimen
Kami memperoleh total 976 kode awal menggunakan pengodean induktif deskriptif dari transkrip. Setelah menyempurnakan penghapusan duplikat, tersisa 660 kode. Saat mengkategorikan kode-kode ini berdasarkan makna yang sama, kami memperoleh 19 subtema yang berisi lebih dari 15 kode pengelompokan. Subtema-subtema ini kemudian diorganisasikan ke dalam 4 tema pengorganisasian: (1) Kesalahan, (2) Kepercayaan, (3) Antarmuka manusia-mesin (HMI) dan (4) Keamanan.
Tabel 3 menunjukkan ikhtisar dari tujuh tema dan subtema masing-masing. Penafsiran terperinci dari hasil akan dibahas bersama dengan hasil eksperimen di bagian pembahasan.
| Tema | Subtema | Contoh kode |
|---|---|---|
| Kesalahan (52) | Peringatan (39) | Alarm palsu; Peringatan tidak cerdas; pelaporan salah; isyarat salah |
| Nona (30) | Deteksi terlewat; abaikan rintangan; pejalan kaki terlewat | |
| Kontrol kendaraan (30) | Pengereman; mengerem tanpa alasan; melaju lurus; mengurangi kecepatan; mengambil alih | |
| Deteksi (24) | Kegagalan deteksi; kesalahan identifikasi; deteksi radar | |
| Temukan kesalahan (21) | Lebih mudah menemukan kesalahan; perhatikan pejalan kaki; persimpangan kosong | |
| Kepercayaan (40) | Ketidakpercayaan (27) | Jangan percaya; tidak pernah percaya; kendaraan yang tidak dapat dipercaya; kepercayaan tidak bertanggung jawab; tidak bersedia (untuk) |
| Perilaku yang berhubungan dengan kepercayaan (27) | Tidak menerima; mengandalkan diri sendiri; mengandalkan penilaian sistem; menilai ulang diri sendiri; mematuhi sistem; bersedia membeli; | |
| Kepercayaan (25) | Cenderung percaya; cukup percaya; percaya pada; bersedia | |
| Ciri Kepribadian (19) | Gelisah; suka berpetualang; antusias; pesimis | |
| Antarmuka manusia-mesin (37) | Membingkai persepsi (35) | Tidak ada perbedaan; lebih mengkhawatirkan; tidak terkesan; tidak menyadari tentang |
| Informasi mengemudi (32) | memperoleh informasi tambahan; informasi terperinci; status konkret dari pengemudian otomatis; mengirim pesan | |
| Fungsionalitas (24) | Tampilkan lebih banyak; lampu pengingat; jelaskan situasinya; tampilan luas; cara berinteraksi | |
| Saran Mengemudi (23) | Saran yang benar; pahami sarannya; tidak butuh saran; | |
| Cara waspada (16) | Suara peringatan; Disajikan dalam tampilan head-up; penjelasan lebih lanjut muncul; tidak cukup terlihat; haptik; koheren | |
| Keamanan (37) | Risiko (31) | Risiko di jalan; risiko; terlibat dalam; mengambil risiko; berbahaya; berisiko |
| dapat diandalkan (30) | Sering melakukan kesalahan; kendaraan yang dapat diandalkan; keandalan rendah; sistem tidak pasti | |
| Konsekuensi (20) | Konsekuensi yang mengerikan; pejalan kaki yang ketakutan; tabrakan dari belakang; kecelakaan; terlalu parah | |
| Skenario (18) | di jalan yang sebenarnya; rintangan dalam skenario; keputusan dalam situasi tertentu; situasi mendesak; lampu lalu lintas; lampu merah | |
| Pengguna jalan (15) | Pejalan kaki; pengendara sepeda; kontak mata; isyarat gerakan; mobil lain; |
4 Diskusi
Meskipun penting untuk terus meningkatkan keandalan ADS, penting juga bagi kita untuk mempelajari cara mendukung kerja sama manusia-kendaraan yang efisien dalam konteks berbagai tingkat dan jenis kesalahan. Hasil dalam studi ini menyoroti bahwa partisipan dalam otomatisasi dengan keandalan yang lebih tinggi memiliki tingkat tindak lanjut yang lebih tinggi (yaitu, kepatuhan) serta evaluasi kepercayaan subjektif (yaitu, Kepercayaan), dan PR pada ADS, dan juga berkinerja lebih baik, seperti RT yang lebih pendek dalam tugas kolaborasi manusia-kendaraan, melintasi berbagai peristiwa bias kesalahan dan pembingkaian, dibandingkan dengan kelompok keandalan yang lebih rendah. Hal ini diharapkan karena model Hoff dan Bashir ( 2015 ) mengungkapkan bahwa keandalan adalah faktor internal utama yang memengaruhi kepercayaan yang dipelajari. Namun, efek keandalan tidak tercermin dalam indikator keberhasilan tugas. Hal ini bertentangan dengan Zhou et al. ( 2022 ), yang menemukan bahwa keandalan yang lebih tinggi meningkatkan kinerja dalam tugas kolaborasi identifikasi manusia-otomatisasi. Salah satu kemungkinan alasannya adalah bahwa dalam eksperimen kami, tugas kolaborasi adalah memilih apakah akan mengerem atau melaju lurus dalam waktu 7 detik, yang jauh lebih sederhana daripada dalam situasi lalu lintas di dunia nyata. Faktanya, peserta berhasil menyelesaikan 98% tugas dalam semua uji coba, yang juga menunjukkan bahwa peserta menganggap serius tugas kolaboratif dan memiliki keandalan respons yang tinggi. Meskipun data keberhasilan tugas tidak signifikan secara statistik, data tersebut tetap menunjukkan distribusi dengan tingkat keberhasilan tertinggi dalam kondisi keandalan tinggi (100%), dan terendah dalam kondisi keandalan rendah (94%).
Namun, tanpa diduga, distribusi skor SA cukup berbeda dengan indikator lainnya. Temuan ini juga tidak sesuai dengan temuan sebelumnya oleh Petersen et al. ( 2019) . ) dan Miller et al. ( 2014 ) bahwa SA dan kepercayaan berhubungan positif, karena fakta bahwa SA yang lebih tinggi memungkinkan pengemudi untuk lebih memahami lingkungan dan memprediksi tindakan di masa depan, mengurangi ketidakpastian dan dengan demikian meningkatkan kepercayaan. Dalam studi kami, skor SA tertinggi berada dalam kondisi keandalan rendah. Dari desain studi percobaan kami, ADS selalu memberikan deteksi dan saran yang benar dalam kondisi keandalan tinggi, yang dapat membuat peserta lebih bergantung pada sistem dan kurang jeli terhadap lingkungan mengemudi, dan pada gilirannya, mengganggu SA peserta. Menurut salah satu peserta dalam kelompok keandalan tinggi, dia hampir berhenti mengamati lingkungan dan mengikuti saran sistem secara langsung dalam beberapa uji coba terakhir karena kinerja kendaraan yang andal. Itu mengonfirmasi apa yang Dixon et al. ( 2007 ) menyarankan bahwa sistem yang sangat andal dapat sangat merusak kemampuan operator untuk memantau status sistem yang tidak diantisipasi, dan pengurangan kemampuan pemantauan dan prediksi dapat lebih merusak SA operator. Disimpulkan bahwa kontribusi pemahaman dan prediksi lingkungan berkendara terhadap kepercayaan peserta pada ADS sebenarnya tidak signifikan, mengingat dampak perubahan nyata dalam keandalan sistem pada pemantauan pengemudi. Meskipun banyak penelitian di masa lalu berfokus pada SA dalam pengemudian otomatis dan telah mencoba merancang HMI kendaraan untuk mendukung SA pengemudi (Kim et al. 2024 ; S. Ma et al. 2021 ), untuk meningkatkan kepercayaan pengemudi pada kendaraan dan keselamatan berkendara (Parasuraman et al. 2008 ; Petersen et al. 2019 ). Namun, dapat ditegaskan bahwa kontribusi pemahaman dan prediksi lingkungan berkendara terhadap kepercayaan peserta pada ADS sebenarnya tidak signifikan, mengingat perubahan nyata dalam keandalan sistem.
Efek bias kesalahan pada SA partisipan juga signifikan secara statistik, dengan skor yang lebih tinggi dalam kondisi kejadian miss daripada dalam kondisi kejadian FA. Penelitian dalam SA berlimpah dalam domain interaksi manusia-otomatisasi, namun pada dasarnya tidak ada tentang bagaimana hal itu berkaitan dengan bias kesalahan. Wawancara pasca-eksperimen memberikan beberapa argumen yang mungkin. Seorang partisipan menanggapi bahwa ia menemukan bias kesalahan FA dan miss dalam uji coba tersebut, dan lebih mudah untuk menemukan kesalahan dalam kejadian miss daripada dalam kejadian FA. Mempertimbangkan lebih lanjut bahwa RT partisipan lebih pendek dalam kejadian miss (1,12 d) daripada dalam kejadian FA (1,45 d) (tidak signifikan secara statistik), dapat disimpulkan bahwa, dibutuhkan lebih banyak waktu dan beban kerja kognitif untuk menemukan kesalahan FA daripada kesalahan miss dalam kejadian mengemudi seperti itu, yang mendorong partisipan untuk lebih memperhatikan dan memproses informasi dalam kejadian FA. Penelitian sebelumnya tentang bias kesalahan telah membuat klaim serupa, bahwa sistem yang rentan terhadap FA dapat membuat operator kurang cenderung untuk memperhatikan seluruh domain otomatis (Dixon dan Wickens 2006 ). Hasil pada bias kesalahan dan SA tidak sesuai dengan prediksi dan memberikan temuan baru tentang pengaruh keandalan dan bias kesalahan pada SA partisipan dalam ADS, yang mengungkapkan bahwa terlepas dari hubungan antara SA dan variabel eksternal, penentu SA tetap merupakan variabel internalnya, yaitu tingkat perhatian dan persepsi skenario.
Wawasan dari data SA dan wawancara juga dapat digunakan untuk menjelaskan tingkat keberhasilan tugas yang lebih tinggi untuk kondisi kejadian gagal dibandingkan dengan kondisi kejadian FA. Karena lebih mudah bagi peserta untuk mendeteksi kesalahan sendiri dalam kejadian gagal, kemungkinan mengoreksi kesalahan dalam kejadian gagal dan berhasil dalam tugas kolaborasi lebih tinggi ketika kedua kesalahan terjadi dengan frekuensi yang sama. Ini cocok dengan temuan sebelumnya bahwa otomatisasi yang rentan terhadap FA lebih merusak kinerja daripada otomatisasi yang rentan terhadap gagal (Bliss dan Acton 2003 ; Maltz dan Shinar 2003 ). Tetapi interpretasi dalam studi ini terutama dari perspektif sindrom “serigala penangis” (Breznitz 1984 ), di mana peringatan FA lebih menonjol sehingga operator dapat mengabaikan peringatan mendatang dari otomatisasi. Ini mungkin bukan penjelasan yang baik untuk tingkat keberhasilan yang lebih rendah dalam kondisi kejadian FA dari studi ini karena saliensi peringatan bias kesalahan telah dimanipulasi menjadi tingkat yang sama (informasi deteksi visual dan saran mengemudi, hitungan mundur auditori dan visual). Faktanya, Rice dan McCarley ( 2011 ) memberikan bukti langka bahwa FA menghasilkan kinerja manusia yang lebih buruk dan menghasilkan penggunaan otomatisasi yang lebih rendah daripada misses, bahkan misses dan FA cocok untuk saliensi persepsi mereka. Mereka menegaskan bahwa misses otomatisasi dan FA mungkin berbeda dalam saliensi kognitif inherennya, tingkat di mana mereka diperhatikan atau diingat, terlepas dari saliensi persepsi. Data saat ini memberikan bukti yang meyakinkan bahwa FA tidak hanya menghasilkan efek pada SA dan RT peserta dalam ADS yang secara kualitatif berbeda dari yang dihasilkan oleh misses, tetapi juga secara kuantitatif lebih berbahaya bagi tingkat keberhasilan tugas daripada misses.
Hasil Trust mengungkapkan perbedaan signifikan antara bias kesalahan, dengan peringkat Trust peserta lebih tinggi dalam kondisi kejadian FA daripada dalam kondisi kejadian gagal. Hal ini bertentangan dengan asumsi dan penelitian sebelumnya bahwa FA akan menghasilkan tingkat kepercayaan subjektif yang lebih rendah daripada kegagalan dalam sistem otomatis (Bahner et al. 2008 ; Bliss dan Acton 2003 ; Dixon et al. 2007 ). Demikian pula, penelitian ini biasanya mengaitkan ketidakpercayaan yang cukup terhadap FA dengan sindrom “serigala menangis”, namun tingkat pemberitahuan partisipan untuk FA dan miss dalam eksperimen kami dapat dianggap identik. Ada juga penelitian yang menunjukkan bahwa miss akan lebih menonjol dan dapat sangat menurunkan kepercayaan ketika sistem melewatkan kejadian yang mudah dideteksi oleh operator (Madhavan et al. 2006 ), karena biaya yang terkait dengan sistem persinyalan yang melewatkan kejadian kritis berpotensi membawa bencana (Chancey et al. 2017 ). Jika peserta dan otomatisasi gagal dalam kejadian kesalahan dalam studi ini, peserta akan menghadapi konsekuensi yang parah, yaitu tabrakan kecil dengan pejalan kaki. Biaya kegagalan ini jauh lebih besar daripada pemberhentian yang tidak sah di persimpangan kosong dalam kejadian FA. Wawancara mengonfirmasi spekulasi ini. Beberapa peserta menyebutkan bahwa konsekuensi tabrakan dengan pejalan kaki tampak terlalu parah. Dan seorang peserta percaya bahwa jika kendaraan mengerem tanpa alasan dalam kejadian FA dalam skenario mengemudi yang sebenarnya, ada kemungkinan untuk mengalami tabrakan dari belakang dengan mobil di belakangnya, dan ia mungkin mempertimbangkan kembali strategi kepercayaannya. Terlepas dari itu, teori kepercayaan, bersama dengan data kepercayaan dan wawancara dalam studi ini, mengonfirmasi bahwa risiko kesalahan sistem kemungkinan memainkan peran kunci dalam menentukan kepercayaan pada otomatisasi. Meskipun tidak jelas dari data kami bagaimana konsekuensi kegagalan di bawah dua bias kesalahan, yaitu, risiko di bawah dua kondisi, memengaruhi kepercayaan peserta.
Data dari studi ini juga mengungkap ketidakkonsistenan dalam beberapa indikator kinerja, yaitu, partisipan lebih cepat berkolaborasi dengan ADS dan lebih berhasil dalam kondisi miss event, tetapi lebih suka mengikuti saran ADS dalam kondisi FA event, meskipun efek bias kesalahan pada tingkat kepatuhan tidak signifikan secara statistik (77% dalam kondisi FA event, 75% dalam kondisi miss event). Hal ini menunjukkan bahwa salah satu indikator perilaku terbaik yang mewakili konsep abstrak kepercayaan adalah kepatuhan, yaitu, apakah akan mengikuti sistem. Sementara indikator kinerja lainnya dipengaruhi oleh banyak faktor. Hal ini dapat sesuai dengan definisi Mayer tentang kepercayaan – kemauan untuk menerima kerentanan (Mayer et al. 1995 ), yang karenanya partisipan memilih untuk mempercayai informasi ADS dan mengikuti sarannya dalam tugas kolaborasi.
Dari perspektif yang komprehensif, data pengukuran subjektif dan kinerja dalam studi ini menunjukkan bahwa bias kesalahan memengaruhi kepercayaan dan persepsi peserta dalam interaksi manusia-kendaraan dalam dua aspek: Pertama, lebih mudah menemukan sistem yang hilang daripada sistem yang membuat FA, sehingga peserta menghabiskan lebih sedikit waktu untuk berhasil dalam tugas, yang menghasilkan SA yang lebih rendah. Kedua, saat kesalahan terjadi dan tugas gagal, peserta merasakan risiko yang lebih besar dalam kejadian gagal daripada kejadian FA dan pada gilirannya cenderung tidak mengikuti dan memercayai ADS pada mereka yang mengikuti uji coba. Apakah ketidakpercayaan subjektif dan perilaku ini akan berdampak negatif lebih lanjut pada SA dan kinerja tugas perlu diperiksa dalam kolaborasi manusia-kendaraan longitudinal.
Akhirnya, ketika membahas aspek positif dan negatif dari pembingkaian, data dari penelitian ini menunjukkan bahwa pembingkaian tidak memengaruhi variabel apa pun dalam hal data, yang berarti efek pembingkaian tidak tercermin dalam kolaborasi manusia-kendaraan. Beberapa peserta di kedua kondisi pembingkaian melaporkan bahwa mereka tidak menemukan perbedaan antara kedua pembingkaian, dan salah satu dari mereka mencatat bahwa ada terlalu banyak percobaan dalam eksperimen tersebut sehingga pada beberapa perjalanan terakhir ia agak mati rasa terhadap pembingkaian. Peserta lain mengatakan bahwa ia ingin memahami tingkat kata keterangan tertentu dalam pembingkaian, dan bahkan mencoba memprediksi pola kemunculan pembingkaian. Kesenjangan dalam penelitian tentang efek pembingkaian dalam otomatisasi membuat hasil ini kurang dalam ruang yang dapat ditafsirkan. Penelitian lebih lanjut perlu dilakukan untuk menentukan apakah efek pembingkaian, yang telah memberikan dampak besar dalam bidang sosiologi dan psikologi, tidak terkait dengan kepercayaan dan kinerja pengguna dalam kolaborasi manusia-otomatisasi.
4.1 Keterbatasan dan Penelitian Masa Depan
Studi terkini menggunakan beberapa pengukuran untuk menguji kepercayaan dalam kolaborasi manusia-kendaraan. Meskipun semua pengukuran terkait dengan kepercayaan, pengembangan beberapa indikator sangat bervariasi dari kepercayaan dalam situasi tertentu, yang mengakibatkan ketidakkonsistenan dalam variabel. Penelitian mendatang tentang kepercayaan dalam otomatisasi harus mempertimbangkan lebih banyak indikator perilaku sebagai variabel dependen, seperti ketergantungan, kepatuhan, dan ketaatan. Mengenai data subjektif, ukuran sampel yang lebih besar dan poin Likert yang lebih tepat dapat meningkatkan distribusi normal data, sehingga memenuhi prasyarat untuk uji parametrik guna menemukan lebih banyak asosiasi dari data, misalnya, efek interaksi antara variabel.
Keterbatasan lainnya adalah bahwa bias kesalahan yang disajikan dalam ADS dalam studi kami adalah dua kejadian, dan merupakan klasifikasi yang kasar. Ketika bias kesalahan diperkenalkan pada pengemudian otomatis di seluruh domain, bias tersebut harus ditempatkan pada kejadian pengemudian tertentu, yang mengakibatkan perbedaan dalam kejadian bias kesalahan dalam hal keunggulan peringatan, biaya kegagalan, dan kesulitan manusia untuk mendeteksi kesalahan. Seperti yang dibahas dalam bab sebelumnya, mungkin bukan bias kesalahan itu sendiri yang memengaruhi kepercayaan pengguna, melainkan elemen-elemennya yang lebih halus. Pemeriksaan kasar bias kesalahan dalam otomatisasi manusia dapat mengarah pada banyak kesimpulan yang bertentangan, seperti kepercayaan pengguna terkadang tinggi dalam sistem yang rentan terhadap FA dan terkadang tinggi dalam sistem yang rentan terhadap kesalahan. Dengan demikian, pekerjaan masa depan tentang bias kesalahan dalam interaksi manusia-kendaraan dapat mencoba untuk menggambarkan dimensi intrinsik bias kesalahan atau untuk mempertimbangkan perancangan pembingkaian untuk menggambarkan kesalahan dan bertujuan untuk menetapkan mekanisme tentang bagaimana bias kesalahan bekerja pada kinerja manusia. Sistem yang rentan terhadap FA dan miss juga harus dipelajari secara berbeda, karena dalam penelitian kami, bukan hanya indikator perilakunya saja yang berbeda, tetapi juga skema psikologis bawaan yang menggerakkan perilaku tersebut.
Terakhir, tugas kolaborasi manusia-kendaraan dalam eksperimen kami ditetapkan dalam simulator mengemudi statis dan hanya satu kendaraan yang dikemudikan oleh peserta yang berada di jalan kota yang disimulasikan. Sementara manipulasi ini dapat mengurangi risiko dan memfasilitasi pengendalian variabel, yang mengarah pada kurangnya persepsi risiko, dan selanjutnya mengurangi kepekaan manusia terhadap keandalan yang dirasakan dan kesadaran situasional yang seharusnya dimiliki peserta di dunia nyata (Walker et al. 2018 ; Xu et al. 2018 ). Ini mungkin salah satu alasan mengapa beberapa efek pada data subjektif dalam penelitian ini tidak signifikan. Di masa mendatang, kami ingin menyempurnakan pengaturan ini dalam percobaan simulasi atau pengujian dalam skenario dinamis multi-jalur dengan kendaraan uji.
5 Kesimpulan
Dalam studi ini, kami secara eksperimental memanipulasi tingkat keandalan sistem, bias kesalahan pada kejadian mengemudi, dan pembingkaian keandalan untuk menyelidiki kinerja pengguna, kepercayaan situasional, keandalan yang dirasakan, dan kesadaran situasional partisipan dalam kolaborasi manusia-kendaraan. Temuan kami berkontribusi pada penelitian tentang anteseden efek keandalan pada kepercayaan pada otomatisasi, yang menunjukkan bahwa tingkat keandalan otomatisasi memiliki dampak penting pada kinerja pengemudi, keandalan yang dirasakan, dan kepercayaan pada kendaraan. Namun, kesadaran situasional pengguna dalam sistem dengan keandalan yang lebih tinggi lebih rendah, yang dikaitkan dengan fakta bahwa keandalan yang tinggi dan pembingkaian sistem yang positif meningkatkan ketergantungan partisipan dan dengan demikian mengurangi kinerja pemantauan mereka terhadap skenario tersebut. Temuan ini memiliki implikasi praktis untuk strategi pengungkapan keandalan sistem mengemudi otomatis.
Kami juga menemukan bahwa kepercayaan pengguna lebih tinggi pada sistem yang rentan terhadap FA daripada kesalahan. Satu kemungkinan penjelasan adalah bahwa studi ini menghilangkan perbedaan dalam hal pentingnya peringatan antara FA dan kesalahan, dan yang lainnya adalah bahwa peserta diperlihatkan konsekuensi dari kegagalan tugas setelah tugas kolaborasi, yang memungkinkan mereka untuk melihat risiko potensial yang lebih tinggi dalam kejadian kesalahan daripada kejadian FA. Temuan tentang bias kesalahan memberikan diskusi mendalam tentang perbedaan variabel internal antara FA otomatisasi dan kesalahan, sehingga memungkinkan generalisasi implikasinya di luar sistem di mana hanya FA yang memiliki peringatan yang menonjol.